Home
People
Events
Research
Publications
Contact
News
Speech
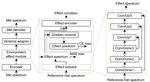
MetaSpeech: Speech Effects Switch Along with Environment for Metaverse
Metaverse expands the physical world to a new dimension, and the physical environment and Metaverse environment can be directly …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
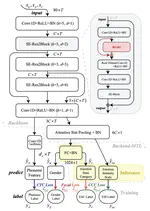
SpeechEQ: Speech Emotion Recognition based on Multi-scale Unified Datasets and Multitask Learning
Speech emotion recognition (SER) has many challenges, but one of the main challenges is that each framework does not have a unified …
Zuheng Kang
,
Junqing Peng
,
Jianzong Wang
,
Jing Xiao
PDF
Cite
arXiv
ISCA
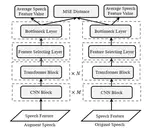
Tiny-Sepformer: A Tiny Time-Domain Transformer Network For Speech Separation
Time-domain Transformer neural networks have proven their superiority in speech separation tasks. However, these models usually have a …
Jian Luo
,
Jianzong Wang
,
Ning Cheng
,
Edward Xiao
,
Xulong Zhang
,
Jing Xiao
PDF
Cite
arXiv
ISCA
Uncertainty Calibration for Deep Audio Classifiers
Although deep Neural Networks (DNNs) have achieved tremendous success in audio classification tasks, their uncertainty calibration are …
Tong Ye
,
Shijing Si
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
ISCA
Speech Augmentation Based Unsupervised Learning for Keyword Spotting
In this paper, we investigated a speech augmentation based unsupervised learning approach for keyword spotting (KWS) task. KWS is a …
Jian Luo
,
Jianzong Wang
,
Ning Cheng
,
Haobin Tang
,
Jing Xiao
Cite
arXiv
IEEE
DT-SV: A Transformer-based Time-domain Approach for Speaker Verification
Speaker verification (SV) aims to determine whether the speaker’s identity of a test utterance is the same as the reference …
Nan Zhang
,
Jianzong Wang
,
Zhenhou Hong
,
Chendong Zhao
,
Xiaoyang Qu
,
Jing Xiao
Cite
arXiv
IEEE
Learning Invariant Representation and Risk Minimized for Unsupervised Accent Domain Adaptation
Unsupervised representation learning for speech audios attained impressive performances for speech recognition tasks, particularly when …
Chendong Zhao
,
Jianzong Wang
,
Xiaoyang Qu
,
Haoqian Wang
,
Jing Xiao
Cite
QSpeech: Low-Qubit Quantum Speech Application Toolkit
Quantum devices with low qubits are common in the Noisy Intermediate-Scale Quantum (NISQ) era. However, Quantum Neural Network (QNN) …
Zhenhou Hong
,
Jianzong Wang
,
Xiaoyang Qu
,
Chendong Zhao
,
Wei Tao
,
Jing Xiao
Cite
arXiv
IEEE
Towards Speaker Age Estimation With Label Distribution Learning
Existing methods for speaker age estimation usually treat it as a multi-class classification or a regression problem. However, precise …
Shijing Si
,
Jianzong Wang
,
Junqing Peng
,
Jing Xiao
Cite
arXiv
IEEE
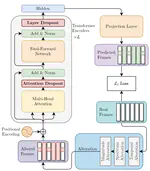
Dropout Regularization for Self-Supervised Learning of Transformer Encoder Speech Representation
Predicting the altered acoustic frames is an effective way of self-supervised learning for speech representation. However, it is …
Jian Luo
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
«
»
Cite
×