Home
People
Events
Research
Publications
Contact
News
Talking Face
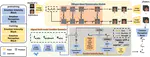
EmoTalker: Emotionally Editable Talking Face Generation via Diffusion Model
In recent years, the field of talking faces generation has attracted considerable attention, with certain methods adept at generating …
Bingyuan Zhang
,
Xulong Zhang
,
Ning Cheng
,
Jun Yu
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
Dataset
IEEE
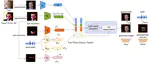
CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding
This paper proposes a talking face generation method named “CP-EB” that takes an audio signal as input and a person image as reference, …
Jianzong Wang
,
Yimin Deng
,
Ziqi Liang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
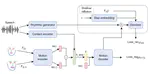
DiffTalker: Co-driven audio-image diffusion for talking faces via intermediate landmarks
Generating realistic talking faces is a complex and widely discussed task with numerous applications. In this paper, we present …
Zipeng Qi
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
Code
arXiv
Shallow Diffusion Motion Model for Talking Face Generation from Speech
Talking face generation is synthesizing a lip synchronized talking face video by inputting an arbitrary face image and audio clips. …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Edward Xiao
,
Jing Xiao
PDF
Cite
Springer
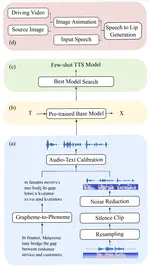
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous …
Aolan Sun
,
Xulong Zhang
,
Tiandong Ling
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Speech2Video: Cross-Modal Distillation for Speech to Video Generation
This paper investigates a novel task of talking face video generation solely from speeches. The speech-to-video generation technique …
Shijing Si
,
Jianzong Wang
,
Xiaoyang Qu
,
Ning Cheng
,
Wenqi Wei
,
Xinghua Zhu
,
Jing Xiao
PDF
Cite
arXiv
ISCA
Cite
×