Home
People
Events
Research
Publications
Contact
News
TTS
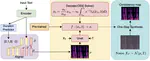
Turbo-TTS: Enhancing Diffusion Model TTS with an Improved ODE Solver
This paper introduces Turbo-TTS, a novel diffusion-based model for text-to-speech (TTS) synthesis. Diffusion models leverage stochastic …
Xulong Zhang
,
Jiashu Wang
,
Xiaoyang Qu
,
Hui Tian
,
Jianzong Wang
Cite
Springer
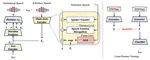
RSET: Remapping-based Sorting Method for Emotion Transfer Speech Synthesis
Although current Text-To-Speech (TTS) models are able to generate high-quality speech samples, there are still challenges in developing …
Haoxiang Shi
,
Jianzong Wang
,
Xulong Zhang
,
Ning Cheng
,
Jun Yu
,
Jing Xiao
Cite
arXiv
Springer
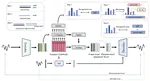
ED-TTS: Multi-Scale Emotion Modeling Using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
Existing emotional speech synthesis methods often utilize an utterance-level style embedding extracted from reference audio, neglecting …
Haobin Tang
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
,
Jianzong Wang
Cite
arXiv
IEEE
DQR-TTS: Semi-supervised Text-to-speech Synthesis with Dynamic Quantized Representation
Most existing neural-based text-to-speech methods rely on extensive datasets and face challenges under low-resource condition. In this …
Jianzong Wang
,
Pengcheng Li
,
Xulong Zhang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
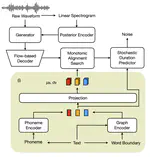
FastGraphTTS: An Ultrafast Syntax-Aware Speech Synthesis Framework
This paper integrates graph-to-sequence into an end-to-end text-to-speech framework for syntax-aware modelling with syntactic …
Jianzong Wang
,
Xulong Zhang
,
Aolan Sun
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
DEMO
EmoMix: Emotion Mixing via Diffusion Models for Emotional Speech Synthesis
There has been significant progress in emotional Text-To-Speech (TTS) synthesis technology in recent years. However, existing methods …
Haobin Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
DEMO
SAR: Self-Supervised Anti-Distortion Representation for End-To-End Speech Model
In recent Text-to-Speech (TTS) systems, a neural vocoder often generates speech samples by solely conditioning on acoustic features …
Jianzong Wang
,
Xulong Zhang
,
Haobin Tang
,
Aolan Sun
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
QI-TTS: Questioning Intonation Control for Emotional Speech Synthesis
Recent expressive text to speech (TTS) models focus on synthesizing emotional speech, but some fine-grained styles such as intonation …
Haobin Tang
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Adapitch: Adaption Multi-Speaker Text-to-Speech Conditioned on Pitch Disentangling with Untranscribed Data
In this paper, we proposed Adapitch, a multi-speaker TTS method that makes adaptation of the supervised module with untranscribed data. …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
Semi-Supervised Learning Based on Reference Model for Low-resource TTS
Most previous neural text-to-speech (TTS) methods are mainly based on supervised learning methods, which means they depend on a large …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
»
Cite
×