Home
People
Events
Research
Publications
Contact
News
TTS
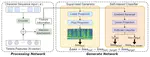
TDASS: Target Domain Adaptation Speech Synthesis Framework for Multi-speaker Low-Resource TTS
Recently, synthesizing personalized speech by text-to-speech (TTS) application is highly demanded. But the previous TTS models require …
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
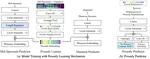
nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-speaker text-to-speech
Multi-speaker text-to-speech (TTS) using a few adaption data is a challenge in practical applications. To address that, we propose a …
Botao Zhao
,
Xulong Zhang
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
r-G2P: Evaluating and Enhancing Robustness of Grapheme to Phoneme Conversion by Controlled Noise Introducing and Contextual Information Incorporation
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Chendong Zhao
,
Jianzong Wang
,
Xiaoyang Qu
,
Haoqian Wang
,
Jing Xiao
Cite
LVCNet: Efficient Condition-Dependent Modeling Network for Waveform Generation
In this paper, we propose a novel conditional convolution network, named location-variable convolution, to model the dependencies of …
Zhen Zeng
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
GraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, …
Aolan Sun
,
Jianzong Wang
,
Ning Cheng
,
Huayi Peng
,
Zhen Zeng
,
Lingwei Kong
,
Jing Xiao
Cite
arXiv
IEEE
MelGlow: Efficient Waveform Generative Network Based On Location-Variable Convolution
Recent neural vocoders usually use a WaveNet-like network to capture the long-term dependencies of the waveform, but a large number of …
Zhen Zeng
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
Cite
arXiv
IEEE
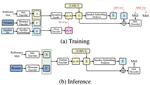
Federated Learning with Dynamic Transformer for Text to Speech
Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Zhenhou Hong
,
Jianzong Wang
,
Xiaoyang Qu
,
Jie Liu
,
Chendong Zhao
,
Jing Xiao
PDF
Cite
arXiv
ISCA
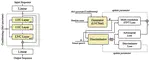
Prosody Learning Mechanism for Speech Synthesis System Without Text Length Limit
Recent neural speech synthesis systems have gradually focused on the control of prosody to improve the quality of synthesized speech, …
Zhen Zeng
,
Jianzong Wang
,
Ning Cheng
,
Jing Xiao
PDF
Cite
arXiv
ISCA
Aligntts: Efficient Feed-Forward Text-to-Speech System Without Explicit Alignment
Targeting at both high efficiency and performance, we propose AlignTTS to predict the mel-spectrum in parallel. AlignTTS is based on a …
Zhen Zeng
,
Jianzong Wang
,
Ning Cheng
,
Tian Xia
,
Jing Xiao
Cite
arXiv
IEEE
GraphTTS: Graph-to-Sequence Modelling in Neural Text-to-Speech
This paper leverages the graph-to-sequence method in neural text-to-speech (GraphTTS), which maps the graph embedding of the input …
Aolan Sun
,
Jianzong Wang
,
Ning Cheng
,
Huayi Peng
,
Zhen Zeng
,
Jing Xiao
Cite
arXiv
IEEE
«
Cite
×