Home
People
Events
Research
Publications
Contact
News
VLM
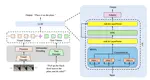
WindowQuant: Mixed-Precision KV Cache Quantization based on Window-Level Similarity for VLMs Inference Optimization
Recently, video language models (VLMs) have been applied in various fields. However, the visual token sequence of the VLM is too long, …
Wei Tao
,
Xiaoyang Qu
,
Peiqiang Wang
,
Guokuan Li
,
Jiguang Wan
,
Kai Lu
,
Jianzong Wang
Cite
arXiv
DIVA: Harnessing the Representation Divergence in Unified Multimodal Models for Mutual Reinforcement
Unified Multimodal models (UMMs) built on a single architecture have shown impressive performance in both understanding and generation. …
Renjie Lu
,
Xulong Zhang
,
Xiaoyang Qu
,
Shangfei Wang
,
Jianzong Wang
Cite
Code
arXiv
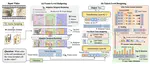
Triage: Hierarchical Visual Budgeting for Efficient Video Reasoning in Vision-Language Models
Vision-Language Models (VLMs) face significant computational challenges in video processing due to massive data redundancy, which …
Anmin Wang
,
Nan Zhang
,
Wei Tao
,
Xiaoyang Qu
,
Guokuan Li
,
Jiguang Wan
,
Jianzong Wang
Cite
arXiv
IEEE
Cite
×