Home
People
Events
Research
Publications
Contact
News
VQA
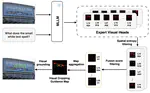
Head-Aware Visual Cropping: Enhancing Fine-Grained VQA with Attention-Guided Subimage
Multimodal Large Language Models (MLLMs) show strong performance in Visual Question Answering (VQA) but remain limited in fine-grained …
Junfei Xie
,
Peng Pan
,
Xulong Zhang
Cite
arXiv
Mita: A Hierarchical Multi-Agent Collaboration Framework with Memory-Integrated and Task Allocation
Recent advances in large language models (LLMs) have substantially accelerated the development of embodied agents. LLM-based …
Xiaojie Zhang
,
Jianhan Wu
,
Xiaoyang Qu
,
Jianzong Wang
Cite
arXiv
Cite
×