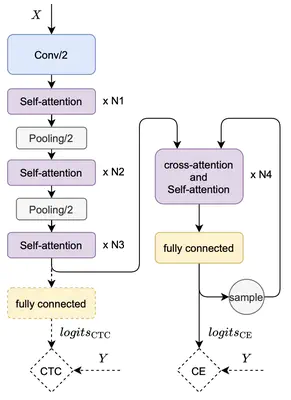
 The ASR model structure we used in this work
The ASR model structure we used in this workAbstract
End-to-end modeling requires tremendous amounts of transcribed speech to achieve an automatic speech recognition (ASR) model with high performance. For low-resource ASR tasks, it is a promising approach to utilize the highly accessible unlabeled speech and text corpus. Previous works have shown that training with pseudo samples, which are the inferring results given the unlabeled speech, can substantially improve the accuracy of a baseline ASR model. Besides the common data filtering to improve pseudo-label quality, we propose an alternative pseudo-sample deliberation method that operates on the output of the ASR model through a pre-trained bidirectional language model (BERT). It fixes the unreasonable tokens in the inference by substitution, which can distill knowledge from the large text corpus. Experiments on Librispeech show that assisted with our fixing operation, self-training on additional unlabeled samples can bridge up to 82.3 % of the gap with the supervised training.