 An overview of the proposed method of SU-net for singing voice synthesis
An overview of the proposed method of SU-net for singing voice synthesisAbstract
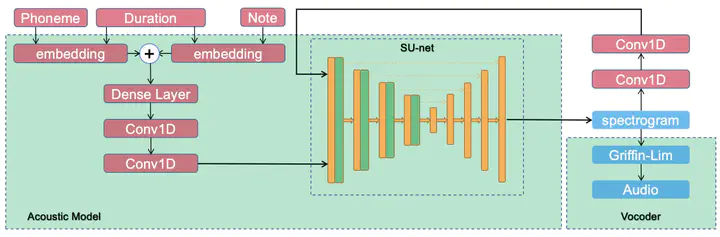
Singing voice synthesis is a generative task that involves multi-dimensional control of the singing model, including lyrics, pitch, and duration, and includes the timbre of the singer and singing skills such as vibrato. In this paper, we proposed SU-net for singing voice synthesis named SUSing. Synthesizing singing voice is treated as a translation task between lyrics and music score and spectrum. The lyrics and music score information is encoded into a two-dimensional feature representation through the convolution layer. The two-dimensional feature and its frequency spectrum are mapped to the target spectrum in an autoregressive manner through a SU-net network. Within the SU-net the stripe pooling method is used to replace the alternate global pooling method to learn the vertical frequency relationship in the spectrum and the changes of frequency in the time domain. The experimental results on the public dataset Kiritan show that the proposed method can synthesize more natural singing voices.