VoiceExtender: Short-utterance Text-independent Speaker Verification with Guided Diffusion Model
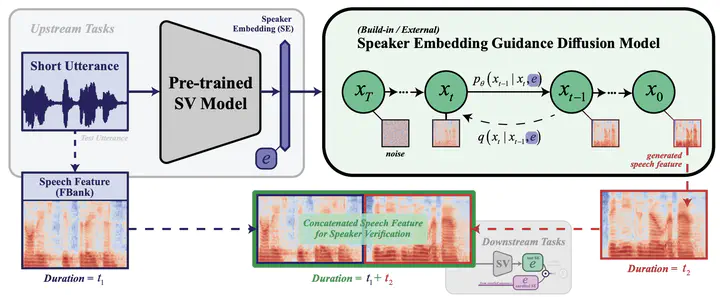 The speaker embedding guidance diffusion model overview
The speaker embedding guidance diffusion model overviewAbstract
Speaker Verification (SV) performance gets worse as utterances get shorter. To this end, we propose a new architecture called VoiceExtender which has two implementations and provides a promising solution for improving SV performance when handling short-duration speech signals. We used two bootstrap diffusion models, the built-in speaker embedding (SE) and the external-SE guidance diffusion model, both of which utilize a diffusion model-based sample generator that leverages SE guidance to augment the speech features based on a short utterance. Extensive experimental results on the Voxceleb1 dataset show that our method outperforms the baseline, with relative improvements in Equal Error Rate (EER) of 46.1%, 35.7%, 10.4%, and 5.7% for the short accent conditions of 0.5, 1.0, 1.5, and 2.0 seconds, respectively.