Feature-Rich Audio Model Inversion for Data-Free Knowledge Distillation Towards General Sound Classification
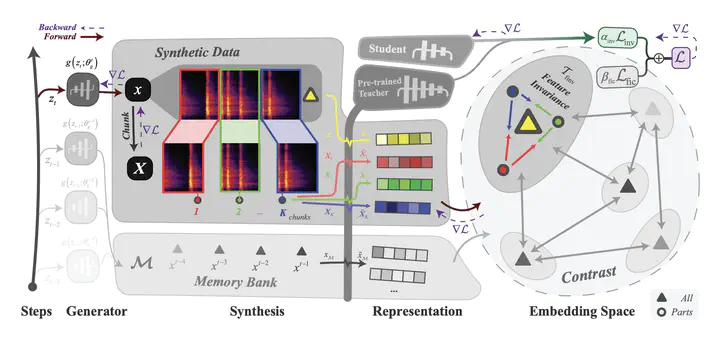 Feature invariance contrastive inversion overview
Feature invariance contrastive inversion overviewAbstract
Data-Free Knowledge Distillation (DFKD) has recently attracted growing attention in the academic community, especially with major breakthroughs in computer vision. Despite promising results, the technique has not been well applied to audio and signal processing. Due to the variable duration of audio signals, it has its own unique way of modeling. In this work, we propose feature-rich audio model inversion (FRAMI), a data-free knowledge distillation framework for general sound classification tasks. It first generates high-quality and feature-rich Mel-spectrograms through a feature-invariant contrastive loss. Then, the hidden states before and after the statistics pooling layer are reused when knowledge distillation is performed on these feature-rich samples. Experimental results on the Urbansound8k, ESC-50, and audioMNIST datasets demonstrate that FRAMI can generate feature-rich samples. Meanwhile, the accuracy of the student model is further improved by reusing the hidden state and significantly outperforms the baseline method.