DQR-TTS: Semi-supervised Text-to-speech Synthesis with Dynamic Quantized Representation
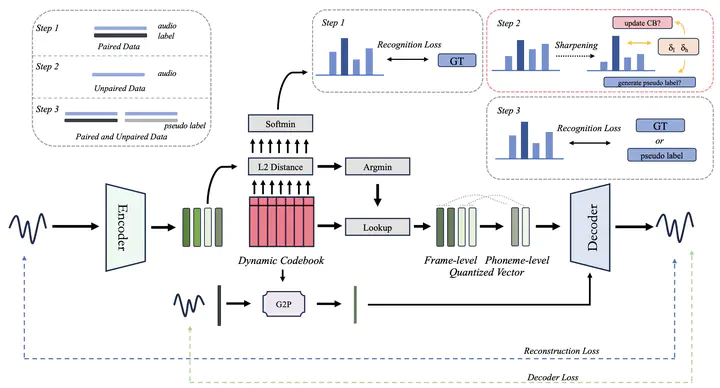 Pipeline of the proposed method
Pipeline of the proposed methodAbstract
Most existing neural-based text-to-speech methods rely on extensive datasets and face challenges under low-resource condition. In this paper, we introduce a novel semi-supervised text-to-speech synthesis model that learns from both paired and unpaired data to address this challenge. The key component of the proposed model is a dynamic quantized representation module, which is integrated into a sequential autoencoder. When given paired data, the module incorporates a trainable codebook that learns quantized representations under the supervision of the paired data. However, due to the limited paired data in low-resource scenario, these paired data are difficult to cover all phonemes. Then unpaired data is fed to expand the dynamic codebook by adding quantized representation vectors that are sufficiently distant from the existing ones during training. Experiments show that with less than 120 minutes of paired data, the proposed method outperforms existing methods in both subjective and objective metrics.