Cross-Language Transfer Learning and Domain Adaptation for End-to-End Automatic Speech Recognition
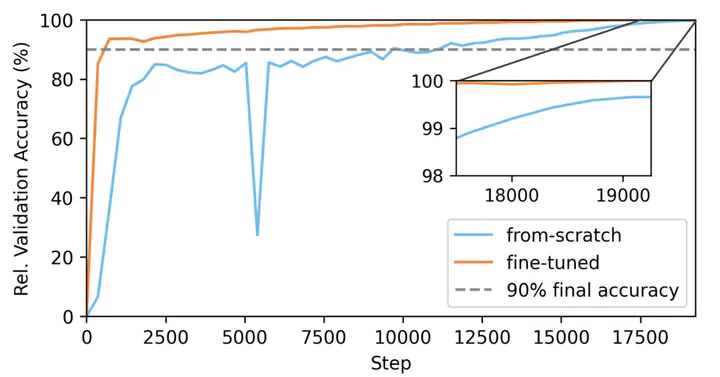 Relative validation accuracy during training
Relative validation accuracy during trainingAbstract
In this paper, we demonstrate the efficacy of transfer learning and continuous learning for various automatic speech recognition (ASR) tasks using end-to-end models trained with CTC loss. We start with a large pre-trained English ASR model and show that transfer learning can be effectively and easily performed on{:} (1) different English accents, (2) different languages (from English to German, Spanish, Russian, or from Mandarin to Cantonese) and (3) application-specific domains. Our extensive set of experiments demonstrate that in all three cases, transfer learning from a good base model has higher accuracy than a model trained from scratch. Our results indicate that, for fine-tuning, larger pre-trained models are better than small pre-trained models, even if the dataset for fine-tuning is small. We also show that transfer learning significantly speeds up convergence, which could result in significant cost savings when training with large datasets.