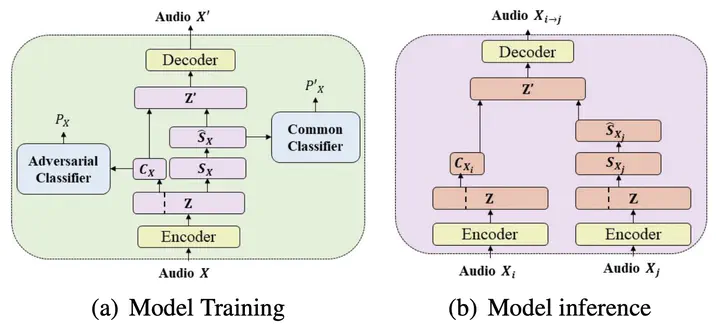
 The framework of the proposed Model
The framework of the proposed ModelAbstract
Non-parallel many-to-many voice conversion is a kind of style transfer task in speech. Recently, AutoVC has been applied in this field as a popular solution, as it can achieve distribution-matching style transfer by training only the reconstruction loss. However, in order to strike a good balance between timbre disentanglement and sound quality, AutoVC requires imposing very strict constraints on the dimensionality of the latent representation. This constraint affects the quality of the converted speech while making it challenging to apply to other datasets directly. This paper proposes a new voice conversion framework that uses only one encoder to obtain timbre and content information by partitioning the latent space in the channel dimension. Furthermore, two different types of classifiers and two additional reconstruction losses are proposed to ensure that different parts of the latent space contain only separated content and timbre information, respectively. Experiments on the VCTK dataset show that the proposed model achieves state-of-the-art results in terms of the naturalness and similarity of converted speech. In addition, we experimentally show that for different division proportions of latent space, the content and timbre information will always be well separated.