From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
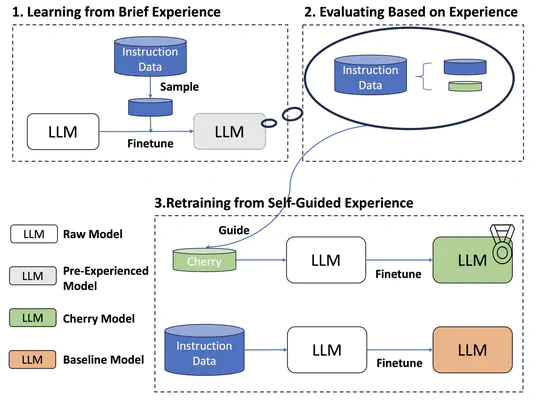 Overview of our proposed method
Overview of our proposed methodAbstract
In the realm of Large Language Models, the balance between instruction data quality and quantity has become a focal point. Recognizing this, we introduce a self-guided methodology for LLMs to autonomously discern and select cherry samples from vast open-source datasets, effectively minimizing manual curation and potential cost for instruction tuning an LLM. Our key innovation, the Instruction-Following Difficulty (IFD) metric, emerges as a pivotal tool to identify discrepancies between a model’s expected responses and its autonomous generation prowess. Through the adept application of IFD, cherry samples are pinpointed, leading to a marked uptick in model training efficiency. Empirical validations on renowned datasets like Alpaca and WizardLM underpin our findings; with a mere 10% of conventional data input, our strategy showcases improved results. This synthesis of self-guided cherry-picking and the IFD metric signifies a transformative leap in the optimization of LLMs, promising both efficiency and resource-conscious advancements. Codes, data, and models are available at https://github.com/tianyi-lab/Cherry_LLM.