MAIN-VC: Lightweight Speech Representation Disentanglement for One-Shot Voice Conversion
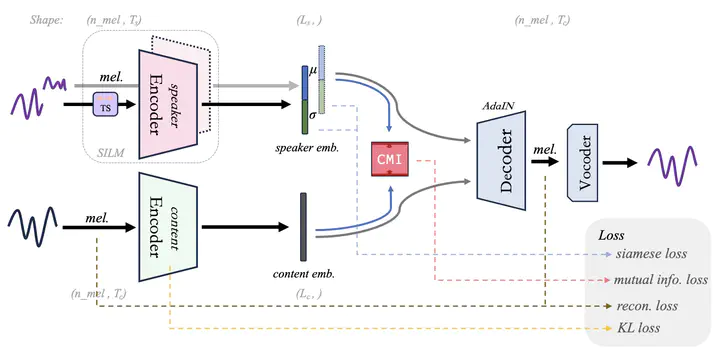 Architecture of MAIN-VC and the training objectives
Architecture of MAIN-VC and the training objectivesAbstract
One-shot voice conversion aims to change the timbre of any source speech to match that of the unseen target speaker with only one speech sample. Existing methods face difficulties in satisfactory speech representation disentanglement and suffer from sizable networks as some of them leverage numerous complex modules for disentanglement. In this paper, we propose a model named MAIN-VC to effectively disentangle via a concise neural network. The proposed model utilizes Siamese encoders to learn clean representations, further enhanced by the designed mutual information estimator. The Siamese structure and the newly designed convolution module contribute to the lightweight of our model while ensuring performance in diverse voice conversion tasks. The experimental results show that the proposed model achieves comparable subjective scores and exhibits improvements in objective metrics compared to existing methods in a one-shot voice conversion scenario.