EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning
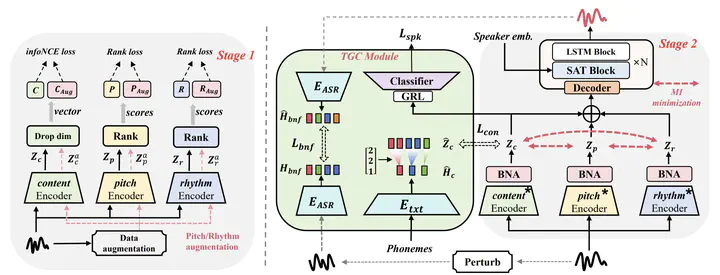 Framework of EAD-VC
Framework of EAD-VCAbstract
Using unsupervised learning to disentangle speech into content, rhythm, pitch, and timbre for voice conversion has become a hot research topic. Existing works generally take into account disentangling speech components through human-crafted bottleneck features which can not achieve sufficient information disentangling, while pitch and rhythm may still be mixed together. There is a risk of information overlap in the disentangling process which results in less speech naturalness. To overcome such limits, we propose a two-stage model to disentangle speech representations in a self-supervised manner without a human-crafted bottleneck design, which uses the Mutual Information (MI) with the designed upper bound estimator (IFUB) to separate overlapping information between speech components. Moreover, we design a Joint Text-Guided Consistent (TGC) module to guide the extraction of speech content and eliminate timbre leakage issues. Experiments show that our model can achieve a better performance than the baseline, regarding disentanglement effectiveness, speech naturalness, and similarity. Audio samples can be found at this https URL.