LLAM
The Lab of Large Audio Model (LLAM) is committed to create innovative solutions that enhance privacy, security, and efficiency in decentralized and complex systems.
Recent News
[28/05/2026] $\bullet$ We are pleased to announce that our paper, “Anti-Aliasing-Aware BigVGAN: Spectral Inversion and Frequency Shuffle for Fast High-Fidelity Neural Audio Vocoding,” has been accepted to JCC 2026! This work studies the unique frequency composition patterns of vocoder generator features and improves BigVGAN by removing anti-aliasing filters in lower-rate blocks, adding spectral inversion modules, and introducing frequency shuffle upsampling. With these modifications, the vocoder achieves better reconstruction quality while delivering faster synthesis speed for audio generation.
[01/05/2026] $\bullet$ We are thrilled to announce that our latest work, “DIVA: Decoupling Visual Representations for Unified Multimodal Understanding and Generation,” has been accepted to ICML 2026! Addressing the pain point where “understanding” and “generation” tasks in unified multimodal models interfere with each other due to differing feature requirements, we propose the DIVA post-training framework. By cleverly decoupling visual representations into “shared” and “unique” information, DIVA transforms conflict into synergy, achieving dual leaps in performance for visual understanding and generation!
[21/03/2026] $\bullet$ We are proud to announce that our paper, “Evolvable Embodied Agent for Robotic Manipulation via Long Short-Term Reflection and Optimization,” has been accepted to IJCNN 2026! This work proposes an evolvable embodied agent framework that combines large vision-language models for richer environmental interpretation and policy planning with a novel long short-term reflective optimization mechanism.
[17/03/2026] $\bullet$ We are thrilled to announce that our paper, “VLA-InfoEntropy: A Training-Free Vision-Attention Information Entropy Approach for Vision-Language-Action Models Inference Acceleration and Success,” has been accepted to ICME 2026! This work introduces a novel training-free method that leverages image entropy to quantify visual token informativeness and attention entropy to capture semantic relevance, enabling dynamic inference acceleration for Vision-Language-Action models by reducing redundancy while maintaining critical spatial, semantic, and temporal cues. Extensive experiments demonstrate significant improvements in inference efficiency and performance over existing approaches.
[11/03/2026] $\bullet$ We are thrilled to share that our latest research paper, titled “From Inheritance to Saturation: Disentangling the Evolution of Visual Redundancy for Architecture-Aware MLLM Inference Acceleration,” is set to be accepted and presented at the upcoming 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026).
Research Direction
Federated Large Models
Research on Federated Large Models focuses on advancing privacy-preserving distributed learning frameworks that enable collaborative training of large-scale AI models across decentralized data sources. This direction integrates cutting-edge techniques in federated learning, differential privacy, and model compression to address challenges in data silos, communication efficiency, and heterogeneous system environments. Key applications include cross-institutional medical analysis, secure financial risk prediction, and edge-device personalized AI services while ensuring strict compliance with data governance regulations.
Trusted Computing
Research on Trusted Computing aims to build secure and verifiable computing systems through hardware-rooted security mechanisms, enclave-based confidential computing, and decentralized trust verification protocols. We focus on designing architectures that guarantee data integrity, execution traceability, and resistance to adversarial attacks across cloud-edge environments. Our innovations are applied to blockchain consensus optimization, privacy-preserving biometric authentication, and AI model provenance tracking, establishing trust foundations for next-generation mission-critical systems.
Graph Computing
Research on Graph Computing explores efficient algorithms and systems for analyzing complex relational data at web-scale. By developing novel graph neural network architectures, dynamic subgraph mining techniques, and heterogeneous graph embedding methods to address challenges in billion-edge network processing, real-time knowledge graph reasoning, and multimodal graph representation learning. Applications span social network fraud detection, drug discovery through molecular interaction networks, and smart city traffic optimization systems.
Large Audio Model
Research on Large Audio Models aims to advance the field of audio processing, generation, understanding, and multimodal processing. This research encompasses a wide range of applications, including speech recognition, virtual assistants, music composition, audio synthesis, and more. Within this broad scope, several key areas of focus include: Low resource TTS, Expressive TTS, Voice Conversion, Audio Caption, Speech Security, and Music AI.
Latest Publication
Unified Multimodal models (UMMs) built on a single architecture have shown impressive performance in both understanding and generation. We identify a fundamental challenge that lies in inductive biases induced by distinct supervision signals generation branch prefers high-fidelity, fine-grained representations capable of reconstruction, while the understanding favours semantically discriminative embeddings that remain invariant to task-irrelevant factors. Consequently, optimizing these complementary but non-equivalent objectives within a monolithic backbone leads to mutual impairment instead of enhancement. In this paper, we first analyze the root cause of this interference in unified backbones and reveal a complementary structure in their internal representations. Motivated by the observation, we propose DIVA, a self-improved post-training framework that transforms the representation divergence into interior synergy. By explicitly factorizing the visual representation into shared and unique components based on two complementary information flow, DIVA enables both the understanding and generation branches to achieve beneficial transferring while preserving the integrity of unique information from cross-flow interference via mutual information estimation. Despite its generality, our method consistently achieves improvements across visual understanding (+7.82%) and generation (+8.46%).
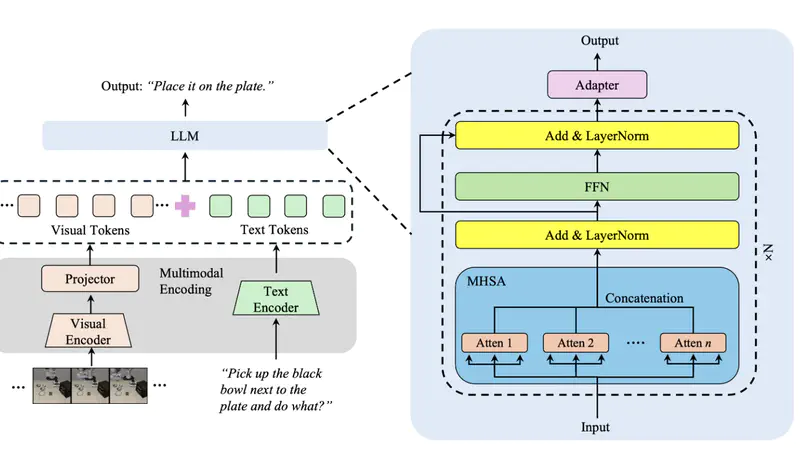
High-resolution Multimodal Large Language Models (MLLMs) face prohibitive computational costs during inference due to the explosion of visual tokens. Existing acceleration strategies, such as token pruning or layer sparsity, suffer from severe “backbone dependency”, performing well on Vicuna or Mistral architectures (e.g., LLaVA) but causing significant performance degradation when transferred to architectures like Qwen. To address this, we leverage truncated matrix entropy to uncover a universal three-stage inference lifecycle, decoupling visual redundancy into universal Intrinsic Visual Redundancy (IVR) and architecture-dependent Secondary Saturation Redundancy (SSR). Guided by this insight, we propose HalfV, a framework that first mitigates IVR via a unified pruning strategy and then adaptively handles SSR based on its specific manifestation. Experiments demonstrate that HalfV achieves superior efficiency-performance trade-offs across diverse backbones. Notably, on Qwen25-VL, it retains 96.8% performance at a 4.1× FLOPs speedup, significantly outperforming state-of-the-art baselines. Our code is available at https://github.com/civilizwa/HalfV.